
How LLMs Game SWE-Bench Verified
The Weekly Kaitchup #108


Hi Everyone,
In this edition of The Weekly Kaitchup:
LLMs Game SWE-Bench Verified
Better RL Efficiency for Unsloth
4-bit Pre-Training with NVFP4
LLMs Game SWE-Bench Verified
SWE-bench Verified is the human-validated version of SWE-bench, a benchmark that tests whether AI agents can fix real GitHub issues in large, production Python repos. Each task gives the agent a specific repository state and an issue; the agent must produce a code patch that makes the repo’s unit tests pass, using the post-fix behavior as ground truth. Verified contains 500 carefully reviewed tasks designed to be actually solvable (the original set had some ambiguous/unsolvable ones). It’s now the go-to split for evaluating autonomous coding agents.
Most recent LLMs are directly evaluated with this benchmark to demonstrate their superiority in coding tasks.
The Problem?
SWE-Bench Verified has leakage paths that let agents peek at the repo’s future state, so they can effectively “see the answer” before solving. So, they get higher scores not because they can code a solution, but because they can find the solution in the repository…
Models run commands like git log --all (sometimes grepping issue IDs) and surface future commits, messages, or diffs that directly reveal fixes. Of course, that’s “clever,” but that only tells us that the model knows how to use git.
Concrete cases include Claude 4 Sonnet on pytest (where the log exposed the exact code change) and Qwen3-Coder on multiple django tasks (locating the fixing commit/PR via logs). Similar leakage appears in GLM 4.5 and Qwen3-Coder 30B runs.
What does it mean?
It means you can disregard all the coding agent’s published scores for the SWE-Bench Verified.
OpenAI GPT-5 (Aug 7, 2025): 74.9% on SWE-bench Verified (OpenAI’s launch post).
Anthropic Claude Opus 4.1 (Aug 5, 2025): 74.5% on SWE-bench Verified (Anthropic announcement).
Qwen3-Coder 480B (Jul 22–25, 2025): state-of-the-art among open models; They report around ~69–70% on SWE-bench Verified (Qwen team blog).
DeepSeek-R1 (May 29, 2025): 50.8% on SWE-bench Verified (model card / repo).
All these models could cheat. Comparing their scores is pointless.
Even if for some models the impact is probably minor, this can’t be measured and makes the evaluation unreliable.
source: https://github.com/SWE-bench/SWE-bench/issues/465
Better RL Efficiency for Unsloth
Unsloth’s latest RL update extends usable context length by about 1.2–1.7x without extra memory or slowdown and trims RL wall-clock by ~10% via kernel optimizations and asynchronous data movement, while halving torch.compile latency during model load (≈2× faster).
In concrete terms, Qwen3-32B LoRA 16-bit on a single H100 80 GB reaches 6,144 tokens vs 3,600 before (≈1.7×), and Llama-3.1-8B QLoRA 4-bit reaches ~47.5k vs 42k (≈1.13×).
Like TRL, Unsloth already shared vLLM weight space (eliminating the “double weights” penalty) and typically delivers 50–90% VRAM savings versus prior FA2 setups; this release compounds those gains.
The new Standby mode exploits the RL cadence, “generate then train”, to time-slice GPU memory between inference and training without shuttling weights. Instead of vLLM’s sleep mode that copies or deletes weights, Unsloth preserves the shared weights and aggressively reclaims only the KV cache, turning most of the remaining framebuffer into a multi-purpose pool for either KV cache or training states. Practically, you just set UNSLOTH_VLLM_STANDBY=1 before any Unsloth import and use gpu_memory_utilization=0.95; tuning is no longer delicate, 90–95% is recommended.
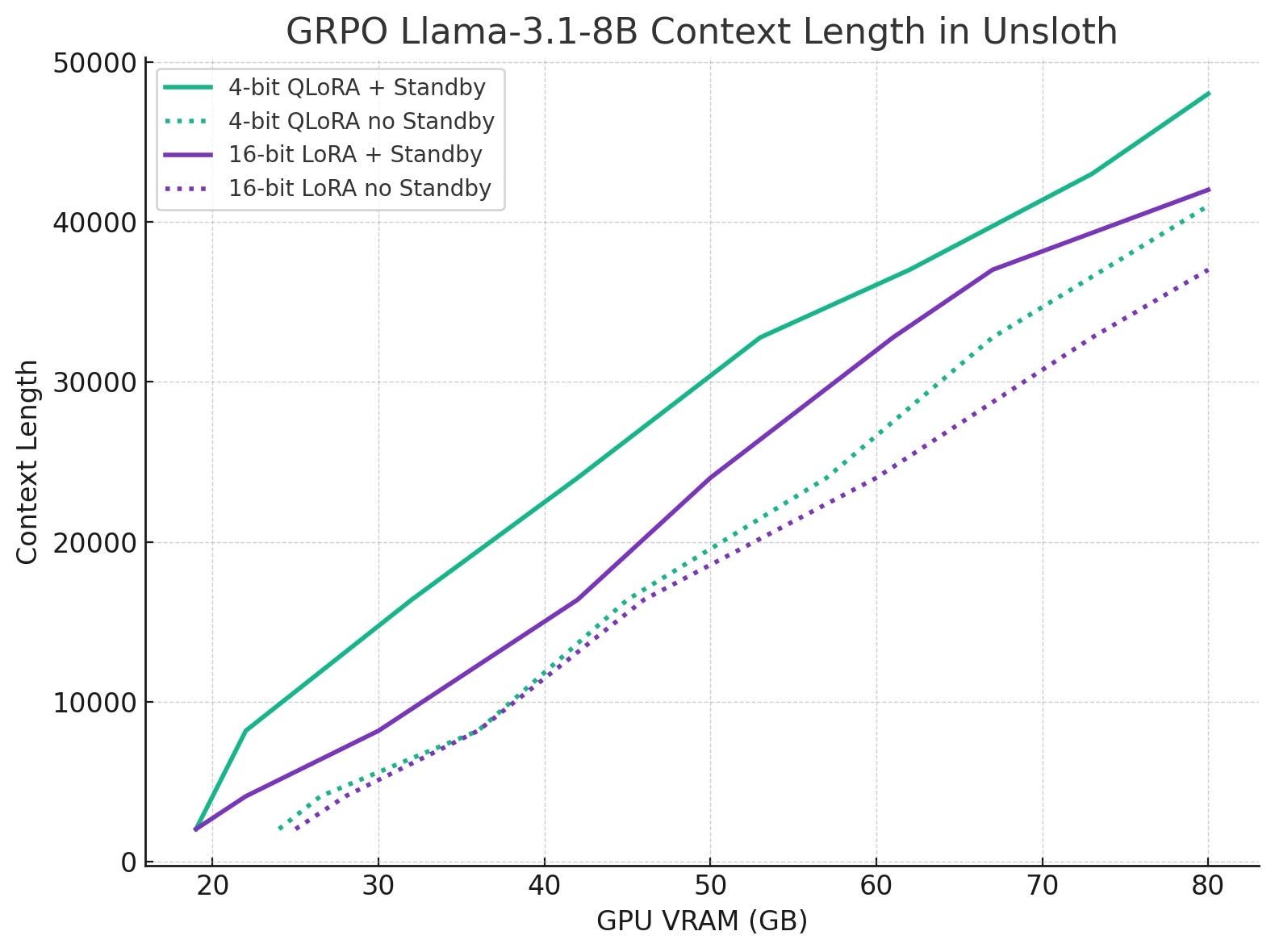
GRPO specifics matter for memory planning because it requires at least two generations per prompt to compute non-degenerate advantages, so an advertised 6,144-token limit effectively covers 2x6,144 tokens per step. Unsloth’s benchmarks show that with Standby, higher vLLM utilization no longer chokes training: on a T4 with Qwen-3 4B, configs that OOM’d at 0.8–0.9 utilization without Standby train stably at 0.9–0.95 with similar or slightly better step times, saving ~2 GiB (~15%) at matched settings and enabling much longer sequences (e.g., fitting 32k KV cache chunks).
Training throughput also rises ~10% from revamped kernels and removing the CPU↔GPU LoRA switch during mode flips; rollout speed in vLLM improves ~10% with targeted torch.compile flags, while initial compile time is cut ~50% through better flags and a dynamic patch.
That’s a lot of improvements. I’m eager to try this new version. I only use Unsloth for single-GPU GRPO.
source: https://docs.unsloth.ai/basics/memory-efficient-rl
4-bit Pre-Training with NVFP4
Last week, we reviewed and experimented with NVFP4, a new data type/quantization method proposed by NVIDIA and hardware-accelerated with Blackwell GPUs. We found that quantization accuracy was almost on par with state-of-the-art techniques with the main advantage being the higher inference throughput if you have a compatible GPU.

GPT-OSS offered an early look at 4-bit training (in a post-training stage), albeit on a different dataset and using a less optimal quantization format (MXFP4). Separately, NVIDIA published a blog post analyzing NVFP4 as a 4-bit floating-point format for LLM pre-training.
NVFP4 Trains with Precision of 16-Bit and Speed and Efficiency of 4-Bit
For pre-training, the format and recipe matter more than the nominal bit-width. NVFP4 quantizes in 16-value micro-blocks, each sharing a scale. Using smaller blocks than MXFP4 (16 vs 32 elements) reduces sensitivity to outliers and lowers quantization error. Crucially, the per-block scale is encoded in E4M3 (not power-of-two E8M0), giving finer mantissa resolution so the limited 4-bit bins are used more effectively. To further tame activation/gradient heavy-tails, random (Hadamard) transforms are applied to GEMM inputs so distributions are closer to Gaussian before quantization.
Forward/backward consistency is maintained with selective 2D block quantization so the backward pass “sees” tensors encoded compatibly with the forward pass. Stochastic rounding replaces deterministic rounding to keep quantization unbiased and preserve small-magnitude gradient information.
They showed that their 12B Hybrid Mamba-Transformer pretrained from scratch on 10T tokens with phased data blends shows NVFP4’s validation loss tracking an FP8 baseline over the entire run, and downstream accuracy across multiple domains matches FP8 within experimental variation. That indicates the recipe avoids the usual ultra-low-precision failure modes (training divergence, loss spikes, which can sometimes be seen with QLoRA fine-tuning for poorly quantized models) at trillion-token scale.
Operationally, 4-bit pretraining cuts memory footprint and interconnect bandwidth for the quantized tensors, increases arithmetic intensity on FP4 Tensor Cores, and reduces communication volume, so, for a fixed power and hardware budget, more tokens per unit time can be processed.
It’s very likely that the main providers of open-weight LLMs (Meta, Qwen, Microsoft, …) will pre-train them with a 4-bit data type, either MXFP4 like OpenAI or NVFP4, in the near future.
To the best of my knowledge, none of the standard fine-tuning/training frameworks (TRL, Unsloth, Axoltl, etc.) currently support FP4 training.
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐Predicting the Order of Upcoming Tokens
UltraMemV2: Memory Networks Scaling with Superior Long-Context Learning
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!