
Fine-tuning LLMs with 32-bit, 8-bit, and Paged AdamW Optimizers
Finding the right trade-off between memory-efficiency, accuracy, and speed


Fine-tuning large language models (LLMs) has become an essential yet resource-intensive task, demanding considerable GPU memory—especially when using the AdamW optimizer, which can quickly consume available resources. For each model parameter, AdamW requires the storage of two additional optimizer states in memory, each typically in float32 format. This translates to an extra 8 bytes per parameter, meaning that for a model with 8 billion parameters, such as Llama 3.1, roughly 64 GB of memory goes solely toward managing optimizer states.

The use of quantized and paged optimizers can significantly reduce memory overhead. Libraries like bitsandbytes have facilitated these memory-efficient approaches, making them increasingly popular.
In this article, we will make a comparative analysis of AdamW-32bit, its 8-bit counterpart, and paged AdamW optimizers, examining their impact on memory consumption, learning curves, and training time. Our goal is to identify when memory-efficient optimizers are essential and evaluate their trade-offs in training speed and model accuracy. In the first section, we will review AdamW 8-bit and its paged variant. Then, we will benchmark each variant of AdamW through Llama 3.1 and 3.2 fine-tuning.
To get the code and experimental logs of fine-tuning with various AdamW configurations for models like Llama 3.1 and Llama 3.2, check out this notebook:
The Cost of AdamW
AdamW is a refined version of the Adam optimizer that is widely used in training LLMs. It specifically addresses a flaw in how Adam handles weight decay, which is important for controlling overfitting and improving the generalization of models.
The AdamW optimizer adjusts the learning rate for each parameter based on past gradients.
Gradients
In machine learning, they show how much the model’s error changes with a small change in each parameter (like weights). By following the gradients in the right direction, optimizers adjust the model parameters to reduce error and improve accuracy during training.
AdamW keeps track of two things during training:
First moment (mean): An exponential moving average of past gradients, which helps guide the optimization in the right direction.
Second moment (variance): An exponential moving average of squared gradients, which scales the updates to avoid large jumps in any direction.
Often referred to as the optimizer states, these two moments have to be computed, and stored, for each parameter of the model. This is why AdamW consumes a large amount of memory. In the default settings, i.e., using the float32 data type for the optimizer states and model’s parameters, the optimizer consumes twice as much memory as the model itself.
For instance, Llama 3.1 8B which has 8.03B parameters will require the optimizer to create 16.06B parameters (8.03B first moments and 8.03B second moments).
Since by default the moments are float32 (4 bytes), the AdamW optimizer states of Llama 3.1 8B consume 16.06*4=64.24 GB.
AdamW 8-bit: Introducing Quantized States
bitsandbytes (MIT license) proposes a quantized version of AdamW, Adamw-8bit.
With this version, the moments are quantized to 8 bits, i.e., 1 byte each. It significantly reduces the memory consumption of AdamW. For instance, for Llama 3.1 8B, instead of consuming 64.24 GB with float32 parameters, AdamW-8bit only consumes, in theory, 64.24/4=16.06 GB.
The drawback is that quantization approximates the moment’s values. Training might be less effective (i.e., higher loss) or unstable in extreme cases. In practice, 8-bit quantization is accurate enough and won’t make much difference in the training performance as we will see in the sections below.
Paged AdamW for Memory-Efficiency
bitsandbytes has also implementations of paged optimizers. Paged optimizers leverage CUDA's unified memory feature.
This works similarly to CPU paging: it only activates when GPU memory runs out, transferring data from GPU to CPU in a page-by-page manner. Memory pages are preallocated on the CPU but aren't updated unless accessed or swapped, meaning the transfer is on-demand rather than continuous.
Compared to CPU offloading, paged optimizers are more efficient. If everything fits into the GPU, there’s zero overhead, and if some memory needs to be moved, the overhead is minimized.
In other words, if there is enough memory available, a paged optimizer will behave closely to the non-paged version. If not enough memory is available to store the optimizer states, the paged optimizer will start paging and the training time will increase due to the transfers between GPU and CPU.
The accuracy of the training should remain the same.
source: https://github.com/bitsandbytes-foundation/bitsandbytes/issues/962
How to Use AdamW 8-bit and Paged AdamW?
The paged and quantized versions of AdamW are supported by Hugging Face Transformers. To use them, make sure you have installed bitsandbytes:
pip install bitsandbytesThen, we simply need to indicate in the TrainingArguments which optimizer version we want to use. This is the "optim" argument:
training_arguments = SFTConfig(
output_dir="./Llama-3.1-8B_"+optim,
optim=optim,
per_device_train_batch_size=bs,
gradient_accumulation_steps=gs,
log_level="debug",
save_strategy="no",
logging_steps=25,
learning_rate=1e-5,
bf16 = True,
num_train_epochs=1,
warmup_ratio=0.1,
lr_scheduler_type="linear",
dataset_text_field="text",
max_seq_length=512,
)We will try the following value for optim:
adamw_torch: The standard AdamW, 32-bit, not quantized and not paged
paged_adamw_32bit: The paged version of AdamW 32-bit
adamw_8bit: The 8-bit (quantized) version of AdamW
paged_adamw_8bit: The paged version of AdamW 8-bit
AdamW 32-bit vs. AdamW 8-bit vs. Paged AdamW
In this section, we will compare the learning curves, memory consumption, and training time using AdamW 32-bit, 8-bit, and paged, for Llama 3.1 8B and Llama 3.2 3B.
Our goal is to assess the effectiveness of optimizer state quantization in terms of accuracy preservation, memory reduction, and its impact on training time. Additionally, with the paged optimizer, we aim to evaluate the extent to which it affects training speed.
The code I used to draw these learning curves and benchmark memory consumption/training time is in the notebook.
I used Google Colab A100 GPU (40 GB) for these experiments.
Learning curves with AdamW


For this fine-tuning, the quantization to 8-bit of the optimizer states seems extremely accurate. We cannot distinguish the learning curves. With both models, AdamW 8-bit achieves the same loss as with AdamW-32bit. This is remarkable and let us think that we might not need to use AdamW at full precision anymore.
Memory Consumption of AdamW for Llama 3.1 and Llama 3.2

With Llama 3.1 8B, only the configurations using the paged optimizer didn’t run out of memory. To fine-tune Llama 3.1 8B with the standard AdamW 32-bit, an 80 GB GPU would have been necessary. Thanks to the paged optimizer, a 40 GB GPU is enough.
With Llama 3.2 3B, we can see that using a paged optimizer also decreases memory consumption by almost 50% for AdamW 32-bit.
Training Time for Llama 3.1 and Llama 3.2
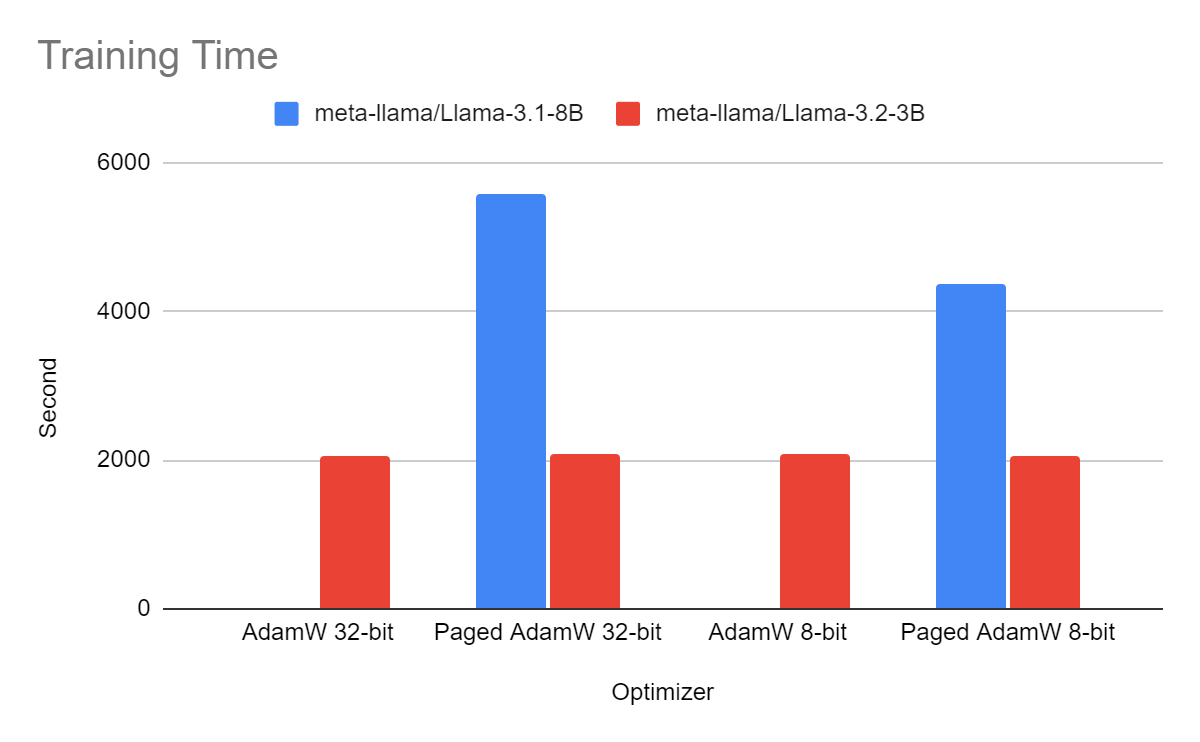
The impact on training time of using a paged optimizer is not noticeable. The unified memory mechanism of NVIDIA GPUs seems very efficient. Moreover, we can observe that, for Llama 3.1, paged AdamW 8-bit is faster than paged AdamW 32-bit. This is intuitive as the 8-bit optimizer states are smaller they are faster to transfer between the GPU and the CPU.
Conclusion
This analysis reveals that quantized and paged optimizers offer a promising path toward making fine-tuning LLMs like Llama 3.1 and Llama 3.2 more memory-efficient without compromising training accuracy or drastically affecting training time. AdamW-8bit optimizers, by reducing state size, save significant memory while maintaining nearly indistinguishable learning curves compared to traditional AdamW-32bit. This result suggests that high-precision optimizer states may be unnecessary for many applications, allowing researchers and practitioners to save valuable resources without a loss in model performance.
Moreover, in cases where paging is needed, using quantized (8-bit) optimizer states can further reduce the latency associated with memory transfers, making paged AdamW-8bit not only memory-efficient but also potentially faster than paged AdamW-32bit. This finding highlights the dual benefit of combining quantization with paging: lower memory usage with minimal impact on training duration.
Overall, quantized and paged optimizers make LLM fine-tuning more accessible and cost-effective.
I don't get the memory consumption. For the 8b model the "paged AdamW 8-bit" needs more memory than the "paged AdamW 32-bit" ??
Thank you. Great explanation. I am now curious which other tricks can be used to fit llama 3.1 8b on a 24GB for full fine tuning. (I saw that Torchtune allows it. )