
Data Preprocessing for Machine Translation
Clean, normalize, and tokenize

Data preprocessing is a critical step for any machine learning task. The data must be correct, clean, and in the expected format.
In this blog article, I explain all the steps that are required to preprocess the data used to train, validate, and evaluate machine translation systems.
I explain each preprocessing step with examples and code snippets to reproduce them by yourself.
For the preprocessing examples in this article, I use the first 100,000 segments from the Spanish-English (Es→En) ParaCrawl v9 corpus (CC0). I directly provide this dataset here (size: 9 MB).
If you want to make this corpus by yourself, follow these steps (be patient, the original dataset is zipped but still weights 24Gb):
#Download the corpus
wget https://opus.nlpl.eu/download.php?f=ParaCrawl/v9/moses/en-es.txt.zip
#Uncompress it
unzip en-es.txt.zip
#Keep only the first 100,000 lines
head -n 100000 ParaCrawlV9.es.txt > train.es
head -n 100000 ParaCrawlV9.en.txt > train.en
#Discard the original files
rm en-es.txt.zipIn my previous article, I presented all the main characteristics of the machine translation datasets used for training, validation, and evaluation:

Data formats: TXT, TSV, and TMX
When looking for datasets for machine translation, you will often find them in different formats that try to best deal with their multilingual nature.
No matter what is the original format, most frameworks for training machine translation systems only take input data in a raw text format.
So you may have to convert the datasets that you got if they are not already text files.
The most common formats that you may find are:
parallel text (.txt): This is ideal. We don’t have to do any conversion. The source segments are in one text file and the target segments in another text file. Most of the following preprocessing steps will be applied to these two files in parallel. In the introduction, we downloaded ParaCrawl in this format.
tab-separated values (.tsv): This is a single file with each pair of source and target segments on the same line separated by a tabulation. Converting it into text files is straightforward with the command “cut”:
#The source segments
cut -f1 data.tsv > train.es
#The target segments
cut -f2 data.tsv > train.enTranslation Memory eXchange (.tmx): This is an XML format often used by professional translators. It is a very verbose format. That’s why it is rarely used for large corpus. Dealing with TMX is slightly more difficult. We can start by stripping the XML tags. To do this, I use a script from the Moses project (LGPL license):
strip-xml.perl < data.tmx > data.txt
#Then we have to remove the empty lines:
sed -i '/^$/d' data.txt
#Finally, we have to separate source and target segments into two files. We can use "sed" to do this:
sed -n 'n;p' data.txt > train.en
sed -n 'p;n' data.txt > train.esDon’t modify the target side of evaluation datasets
Before going further, there is a very important rule to follow when preprocessing datasets for machine translation:
Never preprocessed the target side of the evaluation data!
These are so-called “reference translations.” Since they are “references,” we shouldn’t touch them.
There are several reasons for that. The main one is that the target side of the evaluation data should look like the data you want your system to generate.
For instance, in some of the preprocessing steps, we will remove empty lines and tokenize the segments.
You may want your system to return empty lines, for instance when translating empty text, and certainly, you don’t want to return tokenized texts as a final output of your machine translation systems.
If you remove empty lines from the references, you won’t be able to directly evaluate the ability of your system to generate empty lines when needed. If you tokenize the references, you will only know how good your system is at generating tokenized text. As we will see, tokenized texts are not what you want your system to generate.
Moreover, reference translations are used to compute automatic metric scores to evaluate the machine translation quality. If we modify these translations, we modify the scores. Then, the scores would not be comparable anymore with the other published scores for the same reference translations, since we modified these references.
So keeping the original reference translation is critical to enable the reproducibility and comparability of an evaluation.
If at some point during the preprocessing the target side of the evaluation data is not the same as the original one, it means that something went wrong.
Step 1: Cleaning and Filtering
Step to be applied to: source and target sides of the training and validation data.
For various reasons, publicly available parallel data may require some cleaning.
This is especially true if the data has been automatically created from text crawled on the Web.
Cleaning often implies removing the following segments (or sentences) from the parallel data:
Empty or mostly containing non-printable characters.
With invalid UTF8, i.e., not properly encoded.
Containing extremely long tokens (or “words”) since they are often non-translatable, for instance, DNA sequences, digit sequences, nonsense, etc.
And, sometimes, duplicates, i.e., if a segment, or a pair of segments, appear more than once in the parallel data, we keep only one instance of it.
It is not necessary, but I usually remove duplicates of segment pairs in the training parallel data, for several reasons:
They are rarely useful for training.
They give more weight inside the training data to a particular translation without good reasons.
They are often the unwanted product of a defective process used to acquire the data (e.g., crawling), in other words, these duplicates should never have been there in the first place.
All these filtering rules are applied to keep only what is useful to train a neural model. It also removes segments that may trigger some errors in the following steps of the preprocessing.
They also slightly reduce the size of the parallel data.
Keep in mind that we are cleaning/filtering parallel data. Each filtering rule should be applied to both sides of the data, simultaneously. For instance, if a source segment is empty and should be removed, the target segment should also be removed to preserve the parallelism of the data.
In addition to the rules I mentioned above, we should filter out the segment pairs with:
A very long segment
A very short segment
A high fertility, i.e., when a segment appears disproportionately longer, or shorter, than its counterpart
These rules are inherited from the statistical machine translation era during which these segments were dramatically increasing the computational cost while not being useful for training a translation model.
With the neural algorithms used for training today, these rules are not necessary anymore. Nonetheless, these segments are still mostly useless to train a translation model and can be safely removed from the training data to further reduce its size.
There are many tools to perform this cleaning that are publicly available.
preprocess (LGPL license) is an efficient framework that can do many filtering operations. It is used by the workshop on machine translation to prepare the data for the main international machine translation competitions.
I usually complement it with homemade scripts and additional frameworks such as Moses scripts (LGPL license).
In the following paragraphs, I describe step by step the entire cleaning and filtering process that I usually apply to raw parallel data.
Practice
We want to clean our Paracrawl Spanish-English parallel data (provided in the introduction of this article).
One of the most costly steps, in terms of memory, is the removal of duplicates (so-called “deduplication”). Before deduplication, we should remove as many segment pairs as possible.
We can start by applying the clean-n-corpus.perl (this script doesn’t require installing Moses), as follows: Note: This step assumes the existence of spaces in both the source and target languages. If one of the languages (mostly) doesn’t use spaces, such as Japanese or Chinese, you must first tokenize the source and target text files. If it applies to your use case, go directly to “Steps 2 and 3” and then come back here once it is done.
To know how to use clean-n-corpus.perl, call the script without any arguments. It should return:
syntax: clean-corpus-n.perl [-ratio n] corpus l1 l2 clean-corpus min max [lines retained file]The arguments are:
ratio: This is the fertility. By default, it is set to 9. We usually don’t need to modify it, and thus don’t use this argument.
corpus: This one is the path to the dataset to clean, without the extension. The script assumes that you named both source and target file the same, using the language ISO codes as extensions, for instance, train.es and train.en in our case. If you adopt the same file name convention I used for ParaCrawl, you simply have to put there: “train” (assuming that you are in the directory containing your data).
l1: the extension of one of the parallel files, e.g., “es”.
l2: the extension of the other parallel file, e.g., “en”.
clean-corpus: The name of the files after cleaning. For instance, if you enter “train.clean”, the script will save the filtered parallel data into “train.clean.es” and “train.clean.en”
min: The minimum number of tokens under which a segment should be discarded.
max: The maximum number of tokens above which a segment should be .
max-word-length (not shown here): The maximum number of characters in one token. If a segment pair contains a token longer than max-word-length, it is removed.
To clean our ParaCrawl corpus, the full command to run is:
clean-corpus-n.perl -max-word-length 50 train es en train.clean 0 150This command removes from train.es and train.en segment pairs with:
An empty segment
A segment longer than 150 words (or tokens)
A high fertility
Segments with a word (or token) containing more than 50 characters
And save the results into “train.clean.es” and “train.clean.en”.
The script displays the number of segments removed. If you did the same as I did, it should remain 99976 segments in the data:
clean-corpus.perl: processing train.es & .en to train.clean, cutoff 0–150, ratio 9
……….(100000)
Input sentences: 100000 Output sentences: 99976Note that for each segment removed, its parallel segment is also removed. train.clean.es and train.clean.en should have the same number of lines. You can check it with:
wc -l train.clean.es train.clean.enNext, we remove segments with preprocess.
We need to compile it first (cmake is required):
git clone https://github.com/kpu/preprocess.git
cd preprocess
mkdir build
cd build
cmake ..
make -j4Then, we can use preprocess to remove lines with:
Invalid UTF-8
Control characters (except tab and newline)
Too many Common and Inherited Unicode script characters (like numbers)
Too much or too little punctuation
Too little in the expected script (to remove for instance Chinese sentences in English data)
We use the “simple_cleaning” binary for this. It handles parallel data:
preprocess/build/bin/simple_cleaning -p train.clean.es train.clean.en train.clean.pp.es train.clean.pp.enThe filtered data are saved in two new files that I named “train.clean.pp.es” and “train.clean.pp.en”.
And it should print:
Kept 85127 / 99976 = 0.851474And finally, we can remove duplicates with “dedupe”:
preprocess/build/bin/dedupe -p train.clean.pp.es train.clean.pp.en train.clean.pp.dedup.es train.clean.pp.dedup.enAnd it should print:
Kept 84838 / 85127 = 0.996605We finished cleaning the data.
We nearly removed 15% of the segments. It means that eachtraining epoch of neural machine translation will be 15% (approximately) faster.
Step 2: Normalization
Step to be applied to: the source sides of all the datasets, and potentially to the target side of the training and validation datasets.
The objective of the normalization is to make sure that the same symbols, such as punctuation marks, numbers, and spaces, with the same UTF8 codes, are used in all the datasets.
In practice, this step can also reduce the size of the vocabulary (the number of different token types) by mapping symbols with a similar role or meaning to the same symbol.
For instance, this step can normalize these different quote marks to the same one, as follows:
‘ → “
« → “
《 → “
This step can also make sure that your system won’t generate translations with different styles of punctuation marks if you apply it to the target sides of your training data.
Of course, if we also normalize the target side of the training data, we have to make sure that we map to the desired characters.
For instance, if you prefer “《” because your target language uses this type of quote mark, then you should do a different mapping, as follows:
‘ →《
« →《
“ →《
Since this step is commonly performed when preparing data for machine translation, there are various tools to do it.
I use sacremoses (MIT license). It is an implementation, in Python, of the normalize-punctuation.perl from the Moses project.
Practice
sacremoses normalizer maps dozens of symbols from many languages. The rules can easily be edited to better match your expectations.
sacremoses can be installed with pip (Python 3 is required):
pip install sacremosesThen you can normalize your data with the CLI:
sacremoses normalize < train.clean.pp.dedup.es > train.clean.pp.dedup.norm.es
sacremoses normalize < train.clean.pp.dedup.en > train.clean.pp.dedup.norm.enExamples of differences (obtained with the command “diff”): Note: I took a screenshot instead of copy/paste the sentences in this article because the blog editor automatically applies its own normalization rules.
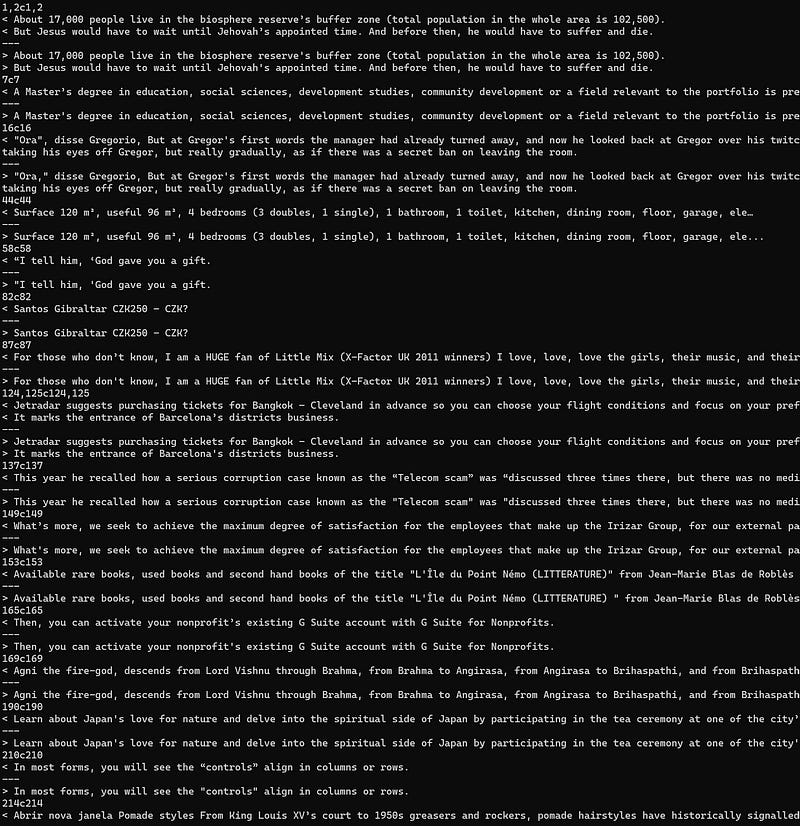
You can pass to this command several options, for instance, if you want to normalize numbers, add the option “-n”. To see all the options run:
sacremoses normalize –helpStep 3: Tokenization
Step to be applied to: the source sides of all the datasets, and to the target side of the training and validation datasets.
Traditionally, datasets for machine translation were tokenized with rule-based tokenizers. They often simply use spaces to delimitate tokens with the addition of rules to handle special cases.
Let’s take an example with the following English sentences:
However, if you deactivate the cookies, you may not be able to access the full range of functions on this website.
Thirty-four retreatants gathered for a Memorial Day weekend of inspiring teachings by Ven.
Facebook: Brisbane City Council - Personal Safety
Tráiler de "The Imaginarium of Doctor Parnassus"
Smoke safety pressure gauge - UNICAL: 04953D
You can also book a holiday rental directly with the property owner or manager.After tokenization with sacremoses tokenizer, we obtain:
However , if you deactivate the cookies , you may not be able to access the full range of functions on this website .
Thirty-four retreatants gathered for a Memorial Day weekend of inspiring teachings by Ven .
Facebook : Brisbane City Council - Personal Safety
Tráiler de " The Imaginarium of Doctor Parnassus "
Smoke safety pressure gauge - UNICAL : 04953D
You can also book a holiday rental directly with the property owner or manager .The differences before and after tokenization are difficult to spot. If you don’t see them, watch for the spaces near punctuation marks.
For several reasons, these rule-based tokenizers are not practical for neural machine translation. For instance, they generate far too many rare tokens that cannot be modeled properly by the neural model.
The data must be “sub-tokenized”. For instance, tokens generated by a traditional tokenizer are split into smaller tokens. This is what the byte-pair encoding approach (BPE) does.
Even more simply, the SentencePiece approach doesn’t even require a traditional tokenization. Consequently, we have one less tool (the traditional tokenizer) to apply and thus one less source of potential errors/mistakes in our preprocessing.
SentencePiece can be applied directly to any sequence of characters. This is especially practical for languages for which spaces are rare such as Japanese, Chinese, and Thai.
Actually, SentencePiece is currently one of the most used tokenization algorithms for large language models such as the ones from the T5 or FLAN families.
Let’s see how it works by taking the same English sentences. We will obtain:
▁However , ▁if ▁you ▁de ac tiva te ▁the ▁cookies , ▁you ▁may ▁not ▁be ▁able ▁to ▁access ▁the ▁full ▁range ▁of ▁function s ▁on ▁this ▁website .
▁Th ir ty - fo ur ▁re tre at ants ▁gather ed ▁for ▁a ▁Me mor ial ▁Day ▁weekend ▁of ▁in spi ring ▁te ach ing s ▁by ▁Ven .
▁Facebook : ▁B ris ban e ▁City ▁Council ▁- ▁Personal ▁Safety
▁T rá il er ▁de ▁" The ▁I ma gin ar ium ▁of ▁Do ctor ▁Par nas s us "
▁S mo ke ▁safety ▁pressure ▁ga u ge ▁- ▁UN ICA L : ▁ 04 95 3 D
▁You ▁can ▁also ▁book ▁a ▁holiday ▁rental ▁directly ▁with ▁the ▁property ▁owner ▁or ▁manage r .The sentences are much more difficult to read by humans and the tokenization isn’t intuitive. Yet, with neural models, it works very well.
To obtain this result, you first need to train a SentencePiece model. The model is then used to tokenize the data, as well as all new inputs that will be sent to our machine translation system.
Practice
To train this model, we first need to install SentencePiece with:
pip install sentencepieceThen, concatenate the source and target sides of your parallel data in one single text file. This will allow us to train a bilingual tokenization model, rather than training different models for the source and target languages.
cat train.clean.pp.dedup.norm.es train.clean.pp.dedup.norm.en > train.clean.pp.dedup.norm.es-enBefore moving on to the training, we must decide on a vocabulary size.
This choice is a difficult but important decision. We usually use a rule of thumb: A value between 8,000 and 16,000 works well for most use cases. You may choose a higher value if you have very large parallel data, or a lower value if you have much smaller training data, for instance, less than 100,000 segment pairs.
The rationale is that if you set the vocabulary size too high, your vocabulary will contain rarer tokens. If your training parallel data doesn’t contain enough instances of these tokens, their embeddings would be poorly estimated.
In contrast, if you set the value too low, the neural model will have to deal with smaller tokens which would have to carry more information in their embeddings. The model may struggle to compose good translations in this situation.
Since our parallel data is quite small, I arbitrarily chose 8,000 for the vocabulary size.
To start the training:
spm_train -input=train.clean.pp.dedup.norm.es-en -model_prefix=es-en.8kspm -vocab_size=8000This should be fast (less than 2 minutes).
The arguments are the following:
input: The data used to train the SentencePiece model.
model_prefix: The name of the SentencePiece model.
vocab_size: The vocabulary size.
Then you have to apply the model to all the data, except the target side of the test set (remember: We never touch this one).
For our ParaCrawl corpus, we do:
spm_encode -model=es-en.8kspm.model < train.clean.pp.dedup.norm.es > train.clean.pp.dedup.norm.spm8k.es
spm_encode -model=es-en.8kspm.model < train.clean.pp.dedup.norm.en > train.clean.pp.dedup.norm.spm8k.enAnd that’s it! Our datasets are all preprocessed. We can now start to train a machine translation system.
Optional steps: truecasing and shuffling
There are two more steps that you may find in some preprocessing pipelines for machine translation: truecasing and shuffling.
Truecasing is getting deprecated but may yield slightly better translation quality. This preprocessing step lowercases characters that are uppercased only due to their position in a sentence.
For instance:
He will go to Canada and I will go to England.
I am not sure why.is truecased as:
he will go to Canada and I will go to England.
I am not sure why.The “h” in “He” is lowercased since it was uppercased only due to its position in the sentence. This is the only difference.
This step slightly reduces the vocabulary size.
sacremoses implements truecasing.
As for shuffling segment pairs, it is probably already integrated in the framework you’ll use to train your machine translation system.
The training data is often automatically reshuffled for each training epoch.
Conclusion
Filtering and normalization are steps that can significantly decrease the computational cost of training neural machine translation.
These steps may also improve the translation quality, especially if the training data is very noisy.
The rules I suggest in this article for filtering and normalization are not suitable for all use cases. They will work well for most language pairs, but you may have to adapt them depending on your languages, e.g., when dealing with Asian languages such as Japanese you may want to change most of the rules for normalization to avoid generating English punctuation marks inside Japanese texts.
Tokenization is even more critical. Fortunately, this is also the step that is most straightforward. Most preprocessing pipelines for machine translation do the same for tokenization, albeit with different hyperparameters.
Hello Sir,
Thank you for all the different tutorials. I have a question about the instruction dataset. In my case, I want to fine-tune, for example, LLAMA3 for extracting features from a given real estate ad. My question is:
Is it better to format the dataset using the prompt format of LLAMA3, or is it okay to use a different format, like the Alpaca format? For example:
"""
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
"""
Could you provide a note discussing how to prepare the dataset?
Thank you!
Can the files train.clean.pp.dedup.norm.spm8k.en and train.clean.pp.dedup.norm.spm8k.es be used for machine translation training as they are? Does the content of the files need to be numericalized for NLP training, meaning that each token is mapped to a unique numerical ID?