BLEU: A Misunderstood Metric from Another Age
But still used today in AI research


GPT-3, Whisper, PaLM, NLLB, FLAN, and many other models have all been evaluated with the metric BLEU to claim their superiority in some tasks.
But what is BLEU exactly? How does it work?
In this article, we will go back 20 years to expose the main reasons that brought BLEU to existence and made it a very successful metric. We will look at how BLEU works with some examples. I will also highlight the main limits of the metric and provide recommendations on how to use it.
This article is thought of as an introduction to BLEU, but can also be a great reminder for seasoned NLP/AI practitioners who use BLEU by habits rather than need.
2001 at IBM
BLEU was first described in an IBM research report co-authored by Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu, in 2001. They published a scientific paper describing it one year later at ACL 2002 which is much more cited and easy to find.
BLEU was originally proposed as an automatic metric to evaluate machine translation (MT).
In 2001, machine translation systems were still mainly evaluated manually, or using older automatic metrics such as WER (word error rate). WER is a metric inspired by the Levenshtein distance and is still used today for the evaluation of speech recognition systems. For machine translation evaluation, WER can be seen as an ancestor of BLEU. The authors of BLEU express it as follows:
We fashion our closeness metric after the highly successful word error rate metric used by the speech recognition community
Like WER, BLEU is a metric that measures how close a text is to texts of reference produced by humans, e.g., reference translations.
Translation being a task with multiple correct solutions, the authors of BLEU designed their metric so that it can handle multiple reference translations. This wasn’t new at that time since WER was already being transformed into an “mWER” to handle multiple references. To the best of my knowledge, it has been first proposed by Alshawi et al. (1998) from AT&T Labs.
It is important to note that, in the entire paper presenting BLEU, the authors always assume the use of multiple reference translations for their metric. They briefly discuss the use of a single reference translation to be correct only under some circumstances:
we may use a big test corpus with a single reference translation, provided that the translations are not all from the same translator.
In contrast, nowadays, most research papers use BLEU with a single reference, often from an unknown origin, and for various tasks, i.e., not only translation.
Since 2001, BLEU has been a very successful metric, to say the least. This was partly due to its cheap computational cost and the reproducibility of BLEU scores, as opposed to human evaluation for which the results can vary a lot depending on the evaluators and the evaluation framework.
BLEU is now used in almost 100% of the machine translation research papers and has largely spread to other natural language generation tasks.
N-gram Matching and Length Penalty
More precisely, BLEU evaluates how well the n-grams of a translation are matching the n-grams from a set of reference translations, while penalizing the machine translation if it is shorter or longer than the reference translations.
Some definitions:
An n-gram is a sequence of tokens. Let’s also define here that a token is a sequence of characters arbitrarily delimited by spaces. For instance, the sentence “a token isn’t a word.” will often be tokenized as “a token is n’t a word .”. We will discuss more on the extremely important role of tokenization later in this article.
To see BLEU in action, I borrowed an example from the BLEU paper of a sentence in Chinese (not provided by the authors) translated into English. We have the following 2 translations generated by machine translation:

And the following 3 reference translations provided by humans:

The question we want to answer with BLEU is:
Which translation is the closest to the given reference translations?
I highlighted all the n-grams that are covered by the reference translations in both candidate translations.

Candidate 1 covers many more n-grams from the reference translations, and since its length (number of tokens) also reasonably matches the length of the reference translations, it will get a higher BLEU score than Candidate 2. Here BLEU is correct since Candidate 1 is indeed better than Candidate 2.
With this example, we can see some obvious limits of BLEU. The meaning of the evaluated translation isn’t considered. BLEU only searched for exact matches with the tokens of the reference translations.
For instance, “ensure” in Candidate 2 isn’t in the reference translations, but “ensures” is. Since “ensure” isn’t exactly the same as “ensures”, BLEU doesn’t reward it despite having a close meaning.
It can be even worse when we closely look at punctuation marks. For instance, Candidate 2 ends with a “.” but this period is attached to “direct.” to form a single token. “direct.” isn’t a token of the reference translations. Candidate 2 isn’t rewarded for correctly containing this period.
This is why BLEU is usually computed on translations that are tokenized to split tokens containing punctuation marks. We will further discuss it in the next section.
To keep it simple, I won’t discuss the equations behind BLEU. If you are interested in computing BLEU by yourself, I invite you to read the BLEU paper where all the equations are well-motivated and explained.
An Infamous Tokenization Dependency
We saw that BLEU is very strict since a token should be identical to a token in the reference translations to count as a match. This is where tokenization plays a very important but often misunderstood role.
The tokenization gives some flexibility to BLEU.
For instance, let’s look again at Candidate 2:
It is to ensure the troops forever hearing the activity guidebook that party direct.
But this time, we apply simple tokenization rules to separate punctuation marks from words. We obtain:
It is to ensure the troops forever hearing the activity guidebook that party direct .
Note that “.” has been separated from “direct” by a space. This is the only difference. Candidate 2 now matches one more token from the reference translations. This token is “.”. It doesn’t seem important since this is only one more token, but this is a very frequent one. This tokenization will have an impact on almost all sentences and thus lead to significantly better BLEU scores.
There is an infinite amount of possible tokenizations. For instance, the following French sentences are translations from English to which I apply 5 different tokenizers. Note: I used Moses (open source, LGPL license) and SacreBLEU (open source, Apache License 2.0).
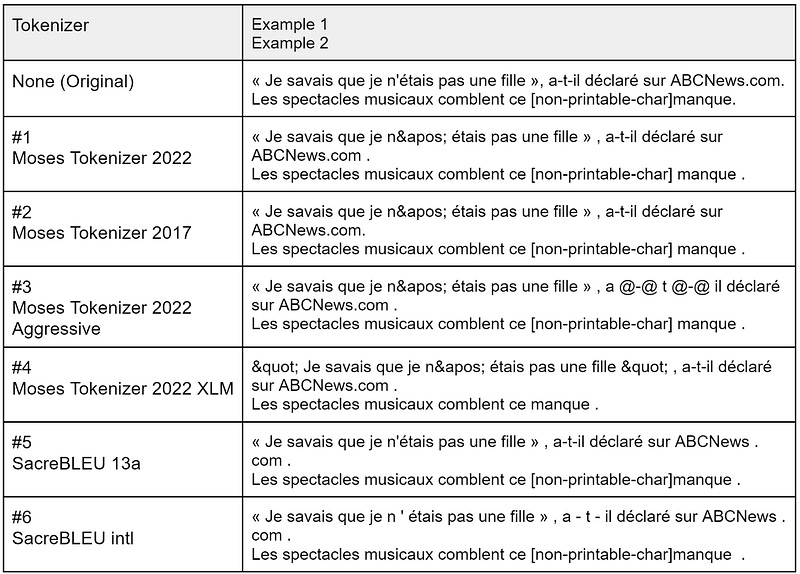
These are the same sentences, but since they are tokenized differently they will match different tokens from the reference translations. All these tokenizations will yield different BLEU scores while the translations remain the same.
This is why two BLEU scores computed on translations for which the tokenization is different, or unknown, can’t be compared.
This is often overlooked in scientific papers nowadays.
You can see the tokenization as a parameter of BLEU. If you change the parameters you change the metric. Scores from two different metrics can’t be compared.
A Metric From Another Age
When BLEU was proposed in 2001, the quality of machine translation was very different.
To give you an idea of this difference, I tried to recreate a French-to-English machine translation system from the 2000s. For this purpose, I trained a word-based statistical machine translation system. I did it with Moses. I will denote this system as “statistical MT (2001).”
Then, I trained a neural machine translation system using a vanilla Transformer model. I did it with Marian (open source, MIT license). I will denote this system as “neural MT (2022).”
The translations they generate are as follows. Note: I highlighted the n-grams matching the reference translation.

As expected, the translation generated by statistical MT doesn’t make much sense, especially towards the end of the sentence. It covers fewer n-grams from the reference translation than neural MT. On the other hand, the translation generated by neural MT looks perfect (without context), but it’s not exactly the same as the reference translation so it will be penalized by BLEU.
In 2001, machine translation systems generated translations that were often meaningless and with obvious syntactic errors. They were rightfully penalized for not matching particular reference translations. Nowadays, neural machine translation often generates very fluent translations, especially for “easy” language pairs such as French-English. They will often find the right translation, but since there are many possible correct translations, finding the exact translation used as a reference may only happen by chance.
This is where we hit the limits of BLEU that will reward only exact matches even when the translation is correct.
When to Use BLEU
BLEU has guided the progress in machine translation research for many years. At NAACL 2018, the authors of BLEU received a test-of-time award.
BLEU is still used in many areas of AI, but only by habit. It is now largely outperformed by many other evaluation metrics for natural language generation tasks, including machine translation, such as chrF, BLEURT, or COMET.
Nonetheless, BLEU remains a very good tool for diagnostic purposes.
Since BLEU has a well-known behavior, i.e., we know what level of BLEU to expect for particular translation tasks, it can be used to quickly spot bugs and other problems in the training pipeline of a machine translation system or in its data processing.
In any case, BLEU shouldn’t be used on short texts. In practice, machine translation practitioners always run BLEU on texts containing more than 1,000 sentences. BLEU is meant to evaluate document translation. It shouldn’t be used to evaluate sentence translation.
As for the implementations of BLEU, many are publicly available. Hugging Face has its own implementation in the Evaluate library. NLTK also implements BLEU. There is also the multi-bleu.perl script in the Moses project. Note that all these implementations of BLEU are different and won’t yield comparable results. My personal recommendation is to use the original implementation of SacreBLEU since this tool was meant to guarantee the reproducibility and comparability of BLEU scores.
And if you plan to use BLEU in your next work, don’t overlook the need to test the statistical significance of your results.